


使用 Next.js 开发一个 seo 友好的网站
写在前面
很多同学可能即使没有用过 next.js 也听说过这个框架。可能大部分人都知道这是一个 react 生态下的 SSR 框架,而大部分人也只是把它当成一个 SSR 框架而已。其实 next 不仅仅是这么简单。
我们平时写得是什么?
对于一个现代的前端开发者,使用 vue 或 react 这样的前端框架(库)来提高开发效率已经是理所当然的事。但是大家有没有想过我们用 react 和 vue 写出来的到底是什么东西?网页么?

从维基百科对网页的定义来看,我们写得当然是网页,但又似乎与传统的网页有点不同。我们似乎很少写 HTML,而是 JavaScript,绝大部分 DOM 都是通过 js 生成的,我们写的网页也很难在搜索引擎中搜到。其实从 SPA 这个名词也能看出来,与传统的网页相比,我们写得更像是应用,只是以网页为载体。
next.js 所做的事,就是让你用现代的前端技术所写的网页应用,看起来更像是传统的网页。
next.js 解决了什么问题?
首先要确定的一点是,nextjs 写出来的也是 SPA,它只返回一次 HTML,后续页面的渲染依然是通过 js 来完成的。但相比于 react,它提供了以下一系列解决方案—
- 提升 SEO 效果。我们知道,使用 react 编写的页面,其渲染是在客户端完成的。通常情况下,除了根节点,html 都通过 js 动态生成,所以对搜索引擎不是很友好,搜索引擎不容易爬取到页面的内容。
next.js提供了服务端渲染(SSR, server-side rendering)和站点静态生成(SSG, static site generation)两种预渲染解决方案,可以让 react 应用在服务端生成请求页面的 html,从而提升 SEO 效果。 - 由于 next.js 会吐一个 html 给前端,不需要前端动态渲染,所以可以提高网站的首屏渲染速度。(你甚至可以在当前页面禁用 js,网站依然可以被渲染!)首屏渲染速度的提升通常是预渲染所带来的附加优点。为什么强调“首屏”呢,因为就像之前说的,其实预渲染方案只有第一次请求才是服务器直接返回完整的 html 的,只要不刷新,后续渲染、路由跳转后页面呈现都是客户端渲染的。
- 使用 next.js 编写的网站往往速度很快,因为它提供了数据预取、代码分割、静态资源优化等功能以提升性能。
- next.js 内置了对
CSS Modules的支持,可直接在组件中 import CSS 文件。还内置了对styled-jsx这一css-in-js库的支持,tailwindcss、styled-component等流行的框架或库也可以很轻松地集成到 next.js 项目中。这让你可以很容易地写出组件级的、可复用的样式而不用担心样式污染等问题。next.js 内置了完善的 webpack 配置,你几乎不需要或仅偶尔需要编写 webpack.config。以上种种努力让你可以开箱即用地开发网站。 - ……
相比于 vue,react 其实只能称为“库”,而不是“框架”,主要原因就是 react 只解决了视图层的问题,你只使用 react,那就只能拿来写 UI,其它一切方案都交给了社区来实现。缺少状态管理?去用 redux 和 mobx,缺少路由管理?去用 react-router…而 nextjs 是一个大而全的框架,常见的问题官方都提供了解决方案。
写这篇文章的时候,其实我构思了很久。
首先,next.js 的语法非常简单,如果你会 react,那上手 next.js 可能仅需要一两天的时间。这会让我觉得“没什么好讲的”。
可是从另一个角度来说,next.js 又对 react 做了非常多的扩展与增强。next.js 的功能如此之多,如果我的文章写得面面俱到,那势必使文章陷入繁杂 api 的泥沼之中。
最终我决定,从顶层出发,介绍一个 seo 友好的网站应该是什么样子,next.js 只是实现一个这样的网站所用到的技术之一。在文章中,我只会介绍无法绕过的 api,如果读者想了解更多优秀的特性,请前往 next.js 官网。官网不仅提供了详细的文档,还有一个快速上手的搭建博客网站的例子,质量非常不错,只是缺少中文支持。
下面进入正题。
文件即路由——next.js 的路由系统
一个 next.js 代码库,最重要的文件夹就是 pages,这个文件夹内包含了网站的全部页面,pages 的文件路径,就是网站的路由。
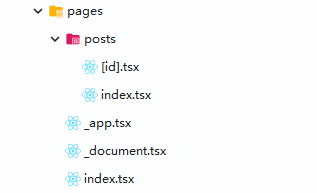
静态路由
根路由文件名为 index,像 pages/index.js,对应的路由就是 /;pages/posts/index.js 对应的路由就是 /posts。这也意味着,假如一个网站路由为 /articles,那你的文件路径既可以是 pages/articles.js,又可以是 pages/articles/index.js。
动态路由
动态路由的文件名称由中括号 [] 包裹,分为两种情况——
-
当动态路由仅有一级时,文件名为
[slug].js。如pages/blog/[slug].js对应路由为/blog/:slug。动态路由也可放在文件路径的中间,如pages/blog/[slug]/hello-world.js对应路由为/blog/:slug/hello-world。你也可以在一条文件路径中并存多个动态路由,像
pages/blog/[slug]/[dynamic].js,对应路由/blog/:slug/:dynamic。注意,文件名
slugdynamic仅为占位符,在实际开发中你可以替换成其它更符合上下文语意的名称。 -
当动态路由为多级时,文件名为
[...slug].js。如pages/blog/[...slug].js对应的路由为/blog/*。此外,还有一种多级动态路由可以被定义为
[[...slug]].js,它和上面的单括号唯一的区别是,是否包含父路径本身。如pages/blog/[...slug].js可覆盖/blog/a、/blog/b、/blog/a/b等路由,而pages/blog/[[...slug]].js除了上面的范围外,还包括/blog。注意,多级动态路由不能放在文件路径中间!
注意事项
静态路由的优先级要高于动态路由。例如,如果你有一个文件为 pages/blog/categories.js,这将匹配 /blog/categories;然后你还定义了一个文件为 pages/blog/[slug].js,这将匹配 /blog/a、/blog/b 等等,但是它不会匹配 /blog/categories。
路由跳转
next.js 提供了 Link 组件用于路由跳转。这种跳转有别于 a 标签,它不会引起页面的重新刷新。
import Link from 'next/link';
const Nav = () => {
return (
<ul>
<li>
{/** 将 Link 组件包裹在 a 标签外面,将 a 标签的 href 属性移到 Link 组件上,值为要跳转的页面路由 */}
<Link href="/">
{/** 在 a 标签上应用 className,而不是 Link 组件 */}
<a className="text-red-500">Home</a>
</Link>
</li>
<li>
<Link href="/blog">
<a>Blog</a>
</Link>
</li>
</ul>
)
};
export default Nav;
绝大多数情况下,建议使用 Link 组件来做跳转,这样的话,next.js 可以检测到当前页面可能会跳转到哪些路由,并提前请求那些页面的 props,来使网站更快地响应。
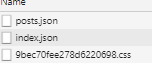
如上图中,在我的博客导航栏中,有两个 Link 组件指向首页和 posts 页,next.js 就预先获取了这两个页面的数据。
通过数据预取,nextjs 的网页跳转甚至比直接请求一份 HTML 更快。
如果你确实需要在别的标签上通过 onClick 的方式跳转的话,next.js 也提供了 useRouter 和 withRouter(hook 和 HOC)来让你使用 router 对象。
一些特殊页面
在 pages 文件夹下,有几个“关键字”是不能随意使用的,它们用来生成一些特殊页面。
自定义 404、500 页
在 pages 根路径下,名为 404 和 500 的页面将成为对应状态展示页面,并且其他页面的 getStaticProps 方法中也可以通过返回 notFound 手动跳转到 404 页面:
const getStaticProps = async () => {
const fetchRes = await fetchData();
if(fetchRes.status === 404) {
return {
notFound: true,
}
}
return {
props: {
fetchRes,
}
}
}
_app
像 react 常写的 App.js 一样,该页面为网站的入口,你可以通过重写该文件来初始化你的网站。在这个页面你可以做一些全局性的操作,比如——
- 添加全局统一的布局(layout)
- 添加全局 CSS
- 添加全局 provider
- ……
_document
你可以在该文件中自定义 html 的结构,包括 <html> <head> <body>。在这里你可以做一些很酷的事情,比如给 <html> 添加 lang 属性以方便支持国际化,或是添加 dark 属性以方便支持暗色模式!
服务端渲染和静态生成——next.js 的两种预渲染方式
next.js 同时支持客户端渲染和预渲染。客户端渲染和在一般 react 项目中没有区别,在组件生命周期中请求数据,将数据在 JSX 中呈现……下面主要介绍预渲染。
说到 SEO,可能很多同学就会想到服务端渲染,而静态生成则没有这么高的知名度。其实服务端渲染和静态生成都是很常用的实现 SEO 的方式。这两种方式被统称为预渲染(pre-rendering)其中的预(pre)就是指在客户端之前预先渲染好页面。
在 next.js 项目中,你甚至可以在控制台禁用掉 js(在 Chrome 中可以输入 ctrl + shift + p 调出 command,输入 Disabled JavaScript),页面依然可以被渲染出来,因为服务器返回给前端的已经是 HTML 文档。
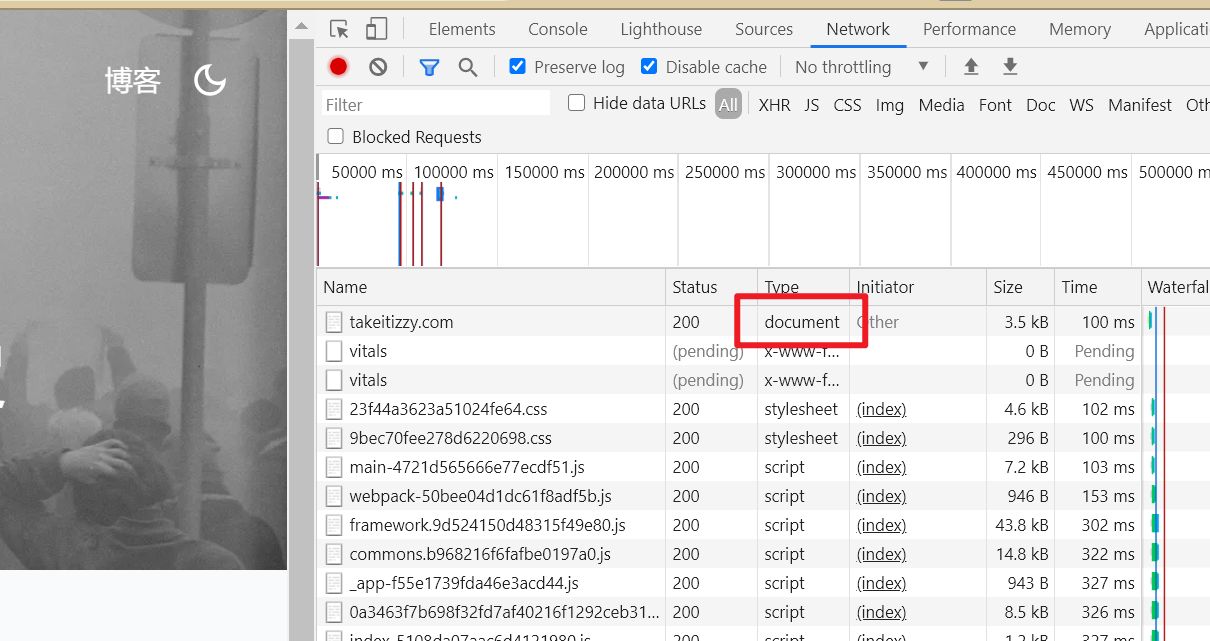
当然,如果你禁用了 js,那通过 js 控制组件在客户端渲染的内容就不会呈现了。
**pre-rendering 是 next.js 最重要的概念之一,而 pre-rendering 中一个关键的步骤,就是获取数据。只要获取到了数据,再结合组件 UI,就可以生成 HTML。**
在 next.js 中,只有页面级组件(pages 文件夹下的文件中,被通过 export default 导出的组件)可以进行预渲染时的获取数据操作。你不能在一个 components 或其它什么文件夹内的通用组件中进行预渲染,而只能在调用它们的页面中获取数据并传递给它们。当然,客户端渲染不受此限制。
在 next.js 中进行预渲染非常简单,你只需要在当前页面组件所在的 js 文件中再 export 一个异步函数即可。这个异步函数用于在合适的时机(前端请求页面时或者代码构建时,这取决于你想让预渲染的方式为服务端渲染还是静态生成)获取数据,并将数据传递给 react 组件。不同的预渲染方式要 export 的函数名称、参数略有不同。
服务端渲染
服务器每次收到请求,都会去获取一次最新的数据,渲染出页面返回给客户端,这种预渲染方式被称为服务端渲染。
// pages/ssr.js
export async function getServerSideProps() {
// Fetch data from external API
const res = await fetch(`https://.../data`)
const data = await res.json()
// Pass data to the page via props
return { props: { data } }
}
如上面代码所示,导出一个 getServerSideProps 函数,该函数返回一个对象,其 props 属性会被注入到 react 组件中——
// pages/ssr.js
const ComponentA = ({ data }) => { // 注意这里,props 中的属性都会被传递给 react 组件
// return JSX by doing sth with data
}
什么时候使用服务端渲染?
虽然服务端渲染更广为人知,但其实它并不是 next.js 官方最推荐的预渲染方式。**你应该仅在需要在每次客户端发起请求时实时获取数据的场景才使用服务端渲染。**而这样选择的原因也是显而易见的,服务端渲染会在每次请求时获取数据,再生成 HTML 文档返回给客户端,响应速度比起静态生成会慢很多。另一个尽量避免使用服务端渲染的原因是,这样页面难以被 CDN 缓存。
静态生成
在代码构建时获取数据并生成页面的方式,被称为静态生成。
与服务端渲染导出一个 getServerSideProps 函数类似,静态生成也需要导出一个 getStaticProps 函数。从函数名也可以看出,其作用应与 getServerSideProps 类似,获取数据并最终返回一个包含 props 属性的对象,并将 props 注入组件中。
动态路由下的静态生成
因为页面是在代码构建时生成的,所以 next.js 在构建时需要知道所有的路由,并遍历每个路由,为他们生成页面。因此,当遇到动态路由时,你需要为 next.js 提供一份列表,告诉 next.js 当前动态路由可能的路由有哪些。这件事是在 getStaticPaths 这个函数中完成的,该函数返回一个对象,并在对象的 paths 属性中返回所有可能的路由值。
// pages/blog/[id].js
export async function getStaticPaths() {
return {
paths: [
{ params: { id: '1' } }, // 该文件为 [id].js,所以这里的属性名也为 id
{ params: { id: '2' } },
],
fallback: true or false // 这里 fallback 的含义稍后会讲到
};
}
具体获取这份路由列表的方法你可以自己决定,如果数据从 CMS 中获得,那你可以去 CMS 中查可能的路由;如果这个动态路由是一篇篇本地文章,那你可以使用 node API 或是第三方库获取所有的文件名,等等。
从上面代码段中可以看到,每个可能的路由值都是一个对象,其中的 params 属性可以类比为 location.params,其中的 id 这个字段具体的名称取决于你文件名中的动态路由为何名称,如果这个路由文件名为 [articleName].js,那 params 的值就不是 { id: 'someValue' } 而是 { articleName: 'someValue' } 了。
增量静态再生成
静态生成这种在代码构建时就生成了页面的方式,其实在数据更新上存在大问题。比如你的页面依赖 CMS 的数据,而 CMS 管理员每次更新页面词条后都需要重新构建代码,这显然是不合理的。
增量静态再生成(ISR, incremental static regeneration)则可以解决这个问题。ISR 让你可以在代码已经构建之后针对每个页面继续使用静态生成,而不是重新构建整个网站。
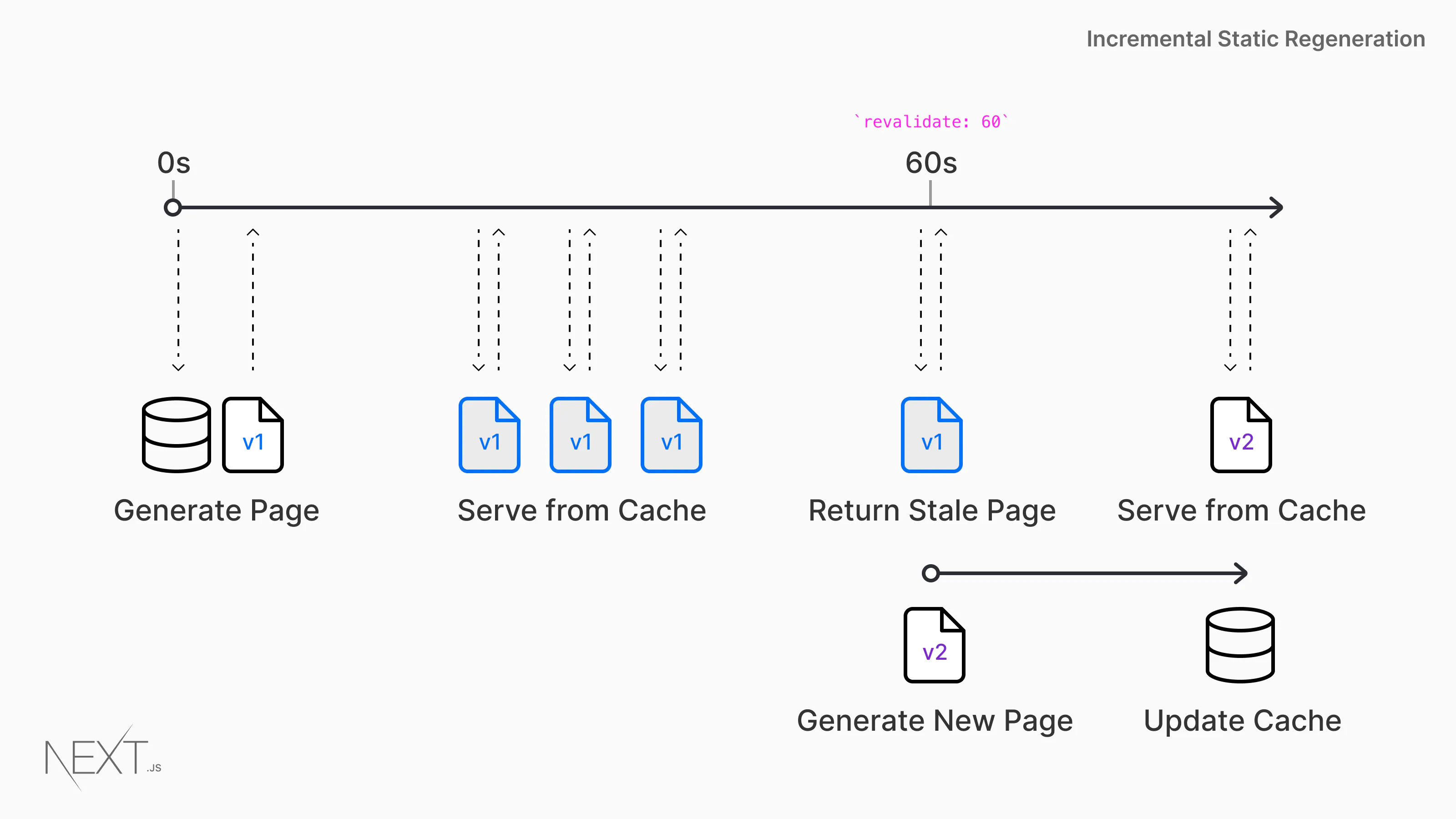
要针对某一页面启用 ISR 非常简单,只需要在 getStaticProps 的返回对象中设置 revalidate 属性即可——
// pages/products/[id].js
export async function getStaticProps({ params }) {
return {
props: {
product: await getProductFromDatabase(params.id),
},
revalidate: 60, // in seconds
}
}
revalidate 的属性值是秒数。假如页面 revalidate 属性值设置为 60,当客户端请求这个页面时,next.js 会返回之前已经生成好的页面,然后在接下来 60s 内的任何请求,next.js 也会返回之前的旧页面。60s 后,next.js 会尝试去重新生成该页面,生成成功,则会返回新页面,并且将新页面缓存以供响应后续请求,否则依然返回旧页面。你甚至可以给页面的 revalidate 设置为 1,这样当有客户端请求 1s 后,页面就会变更为最新的数据。
除了解决数据更新的问题,ISR 还在动态路由页有着巨大的好处。
getStaticPaths 这种提供可能的路由列表的模式,其实是有局限性的。想象你需要开发一个电商网站,商品的数量是极其庞大的,并且无时无刻不在变化。先不说你能否提供一份完整的路由列表,即使你可以提供,那庞大的页面数量也会让你的代码构建永无止尽。而有了 ISR,你可以在代码构建时只构建前 1,000 种热门商品介绍页,剩下的页面可以等待用户请求时再构建。而要做到这点,在 getStaticPaths 的返回对象中,除了返回 paths,你还需要返回一个 fallback 字段,并指定值为 true 或 blocking:
// pages/products/[id].js
export async function getStaticPaths() {
const products = await getTop1000Products()
const paths = products.map((product) => ({
params: { id: product.id },
}))
return { paths, fallback: 'blocking' }
}
true:当客户端请求一个不存在于 paths 的路由时,next.js 会先提供一个页面,通常是展示 loading,并同时在服务端尝试生成该页面,如果成功的话会进入页面,并将该页面缓存下来。blocking:当客户端请求一个不存在于 paths 的路由时,next.js 会在服务端尝试生成该页面,如果成功的话会进入页面,并将该页面缓存下来。在此过程中,页面一直处于阻塞中。(和 SSR 很像,只不过请求过一次后就会将页面缓存下来,而 SSR 不会)
一个 seo 友好的网站要做到什么?
知道了如何通过文件路由系统组织页面,也知道了如何通过两种预渲染方式获取数据(当然你也可以使用客户端请求),你已经可以使用 next.js 开发网站了,其它的开发方式和 react 大同小异。
再次强调,本博客不会穷尽 next.js 那些好用的高级特性及其为构建高效网站所做的努力,如果你想了解更多,请前往 next.js 官网(我强烈推荐你这么做!)如果你已经开发好了网站,却为如何部署它而感到头疼,那我建议你读一读 部署 一节。你可以自己起一个 node 服务,部署在自己的服务器上,或者——也是 next.js 官方推荐的——通过 vercel 这个神奇的平台来做 CI,如果你条件允许的话。这是个非常强大的服务,可以通过 webhook 自动构建部署最新的代码,可以为你的网站提供域名,可以提供 https 服务,甚至还可以进行网站的访问监测和性能跑分。有非常多的产品文档网站和官网托管于这个平台上,唯一的缺点,部署于此的网站,对于国内访问不太友好(其实也不能说是 vercel 的缺点……)。
那么下面,就让我来说说一个 SEO 良好的网站需要做哪些事情。
让你的网站被搜索引擎收录
如果你没有向搜索引擎提供过你的网站,那你的网站将只能通过链接进行访问,在搜索引擎的搜索栏中是无论如何搜索不到你的网站的。而事实上,至少有 50% 的用户访问都通过自然搜索触达。
我以我的个人博客举例介绍如何让网站被搜索引擎收录。由于我的博客使用 vercel 部署,天生无法在国内访问,所以也没必要被百度收录,我只介绍一下谷歌的收录方法,百度应该也大同小异。
首先你要有一个谷歌账号,然后前往谷歌搜索控制台。
点击“立即使用”按钮,如果当前谷歌账号还没有提交过网站,会进入验证页面,填入要被收录的网站域名,并且按照页面介绍的方法进行验证,验证通过后,你就可以通过谷歌搜索到你的网站了。
TDK
TDK,指的是 title description 和 keywords。这是对于 SEO 来说最重要的字段。
通常的手段,你可以通过 next.js 提供的 Head 组件来做这件事,在该组件中所写的标签最终会被加入到 html 的 <head> 中去。
import Head from 'next/head';
const Page = () => {
return (
<>
<Head>
<title>{页面标题}</title>
<meta name="description" content="如何提升 SEO" />
<meta name="keywords" content="next.js, seo, react" />
</Head>
<main>页面内容</main>
</>
);
};
export default Page;
更合理的办法,是把 TDK 放在一个 layout 组件中,这样可以减少你每个页面间的模板代码——
// layout.js
import Head from 'next/head';
const Layout = ({ seo, children }) => {
return (
<>
<Head>
<title>{seo.title}</title>
<meta name="description" content={seo.desc} />
<meta name="keywords" content={seo.keywords} />
</Head>
<main>{children}</main>
</>
);
};
export default Layout;
// page.js
import Layout from 'components/layout';
const Page = () => {
return (
<Layout seo={{
title: '页面标题',
desc: '如何提升 SEO',
keywords: 'next.js, seo, react',
}} >
{/* 页面内容 */}
</Layout>
);
};
export default Page;
sitemap
sitemap,也就是网站地图,这是一份 xml 文件,你可以在其中提供与网站中的网页、视频或其他文件有关的信息,还可以说明这些内容之间的关系。通常情况下,搜索引擎可以根据网页上的链接获取到要跳转到的网页的内容。但是,如果你的网站规模较大(超过 500 个页面),或是有很多没有在任何其它页面中留下链接的页面,此时为网站添加 sitemap 可以让搜索引擎更容易索引以及更高效地爬取你的网站。(看到了吗,外链是很重要的让搜索引擎获取你页面内容的办法,多在其它被搜索引擎收录的网页中为你的网站引流吧!)
下面介绍几种常用的生成 sitemap 的方法。
构建时静态创建 sitemap
在每次构建代码时创建一份 sitemap,是比较常规的做法。你需要先扩展一下 webpack 配置——
// next.config.js
const generateSitemap = require('./libs/gemerateSitemap');
module.exports = {
webpack: (config, { isServer }) => {
if (isServer) { // 是否在服务端编译
generateSitemap();
}
return config;
}
};
我们并没有修改 webpack 的 config,只是在返回之前多执行了一步操作。
网上也有一些 npm 包用来生成 sitemap,不过周下载量都不太高,下面我们来自己实现一下生成 sitemap,这需要用到一个可以遍历文件的库——globby。
const fs = require('fs');
const globby = require('globby');
const generateSitemap = async () => {
const pages = await globby([
'pages/**/*.{js,ts,tsx,mdx}', // pages 下的所有页面,后缀名是自己情况而定
'!pages/**/[*.{ts,tsx}', // 忽略动态路由页面
'!pages/_*.{ts,tsx}', // 忽略如 _app,_document 这样的页面
'!pages/api', // 忽略 api 路由
... //忽略其他你不想添加到 sitemap 中的页面
]);
const urlSet = pages
.map((page) => {
// 格式化,去掉文件后缀,去掉最开始的 'pages'
const path = page
.replace('pages', '')
.replace(/(.js|.tsx|.ts|.mdx)/, '');
// 去掉每个文件夹中的 index 文件的 '/index'
const route = path === '/index' ? '' : path;
// 返回该页面的 xml
return `<url><loc>https://codebycorey.com${route}</loc></url>`;
})
.join('');
// 将所有页面的 xml 加入其中
const sitemap = `<?xml version="1.0" encoding="UTF-8"?><urlset xmlns="http://www.sitemaps.org/schemas/sitemap/0.9">${urlSet}</urlset>`;
// 创建 sitemap.xml 文件
fs.writeFileSync('public/sitemap.xml', sitemap);
};
module.exports = generateSitemap;
上面忽略了动态路由页,如果你需要将其加入,视你的情况来编写代码,如果你的动态路由是一篇篇静态 md 文件,那你需要读取一下这些文件并像上面代码一样进行格式化;如果你的动态路由数据来自 CMS,那就像你的 getStaticPaths 中的请求方法一样请求一遍所有路由列表,然后生成对应的 xml。
在倒数第四行,可以看到我将 sitemap 文件放在了 public 文件夹下,你的 nextjs 项目中的一切静态资源都应该放在该文件夹下。nextjs 对其做了优化,当你使用静态资源时,你可以从 base url(/)引用资源,而不是 public。比如有一个图片路由为 public/images/an-image.png,你可以这么使用它:<img src=“images/an-image” />。在最终构建部署好的网站上,你也可以直接请求对应的路由访问该静态资源:https://your-domain/images/an-image.png。这非常有用,因为如果你需要在服务器根目录新增静态资源(比如上面搜索引擎收录时需要你上传一份验证文件),要么你真的在服务器上传一份静态文件,要么你要使用一个 node 服务用于提供文件。而有了 nextjs 的静态资源优化,只需要将其放在 public 文件夹下,在构建完成后它就会存在于服务器的根目录下。
通过 api 路由生成 sitemap
当网站的页面依赖于 CMS 时,仅在构建时生成 sitemap 很难满足我们的需要。因为 sitemap 一旦生成,除非手动管理文件,否则无法响应新的数据。这时我们需要一种更加动态的方法,那就是使用一个特定的 api 路由来生成 sitemap。
next.js 提供了 api 路由,使用起来很像 express 的 api 路由。next.js 约定,只要是在 pages/api 下的文件,nextjs 则不将其理解为网站页面,而是 api 路由。
// pages/api/generate-sitemap.js
export default async (req, res) => {
// 从 CMS 等外部系统请求资源,很像在 getStaticPaths() 中请求数据
const externalPosts = await fetch('get-pages-url');
const routes = externalPosts.map((post) => `/blog/${posts.slug}`);
const localRoutes = ['/index', '/blog'];
const pages = routes.concat(localRoutes);
const urlSet = pages
.map((page) => {
const path = page
.replace('pages', '')
.replace('_content', '')
.replace(/(.tsx|.ts)/, '')
.replace('.mdx', '');
const route = path === '/index' ? '' : path;
return `<url><loc>https://codebycorey.com${route}</loc></url>`;
})
.join('');
const sitemap = `<?xml version="1.0" encoding="UTF-8"?><urlset xmlns="http://www.sitemaps.org/schemas/sitemap/0.9">${urlSet}</urlset>`;
res.setHeader('Content-Type', 'text/xml');
res.write(sitemap);
res.end();
};
现在只要向 /api/generate-sitemap 发送请求,就会请求最新的数据并返回一份 sitemap 啦!
最后一步,使用路由重写功能,让路由看起来更像是在请求一份静态文件——
// next.config.js
module.exports = {
async rewrites() {
return [
{
source: '/sitemap.xml',
destination: '/api/generate-sitemap'
}
];
}
};
现在 /api/generate-sitemap 就被重写为了 /sitemap.xml。搜索引擎请求 https://www.your-site.com/site map.xml,获得一份 xml 文件,这样的行为就像是在请求一份静态文件,但此时服务器上其实并没有真的存在一份静态文件,这件事是通过 api 路由实现的。
api 路由其实可以做很多事,你甚至可以把它当作一个 BFF 层来响应你的客户端请求(而不是 pre-render),这能避免烦人的跨域问题。
robots.txt
最后一个要介绍的可以提高你网站 SEO 效果的东西就是 robots.txt。这份文件告诉搜索引擎,你希望哪些路由需要被索引,哪些则不需要。
在 public 文件夹下新建一份 robots.txt 文件:
User-agent: *
Disallow:
Sitemap: https://your-domain/sitemap.xml
上面的文件告诉搜索引擎,它可以爬取整个网站。
如果你不想让搜索引擎爬取某些页面,将它们加入 Disallow 中——
User-agent: *
Disallow: /secret-page
Disallow: /another-page
Sitemap: https://your-domain/sitemap.xml
值得一提的是,robots.txt 仅相当于一个君子协议,即使你声明了哪些页面不允许被爬取,爬虫依然可以爬取那些页面。
将你的 nextjs 应用转换为 PWA
这一节是我个人夹带的一点私货,因为我觉得 PWA 很好玩,所以专门拿出来一节讲讲如何将 nextjs 应用转换为 PWA。

Progressive Web App,渐进式 web 应用,简称 PWA。它既可以像网站一样跨平台,又可以像 App 一样离线运行,可以被安装于桌面,在操作系统中被搜索到,甚至和别的 App 交互以及作为特定文件类型的默认打开程序。PWA 兼具了原生 App 和 web 的优点。即使你的网站跑在不支持 PWA 的浏览器中,也没有任何影响,而在支持 PWA 的浏览器中则可以获得相应的能力。PWA 是一项很有野心的技术,依赖于越来越完善的 web api 和如 WebAssembly 这样的新技术,也许未来的某一天,我们的桌面和移动设备上将不再需要安装几十上百个 g 的原生 App。
现在国外已经有越来越多的网站支持 PWA 了,比如 Twitter、Spotify、Starbucks 等,跟前端程序员比较贴近的比如 webpack 官网。
如果你使用 lighthouse 测试过你的网站,那你一定见过其中一个指标:
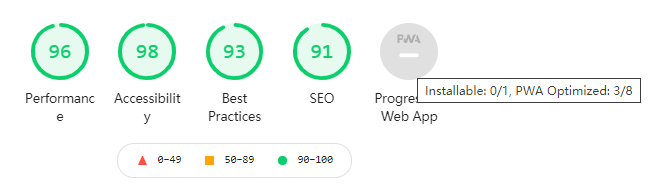
这个指标就是表示你的网站是否支持 PWA。如果一个网站支持 PWA,在用户使用支持 PWA 的浏览器打开网站时,会弹出安装应用的提示——
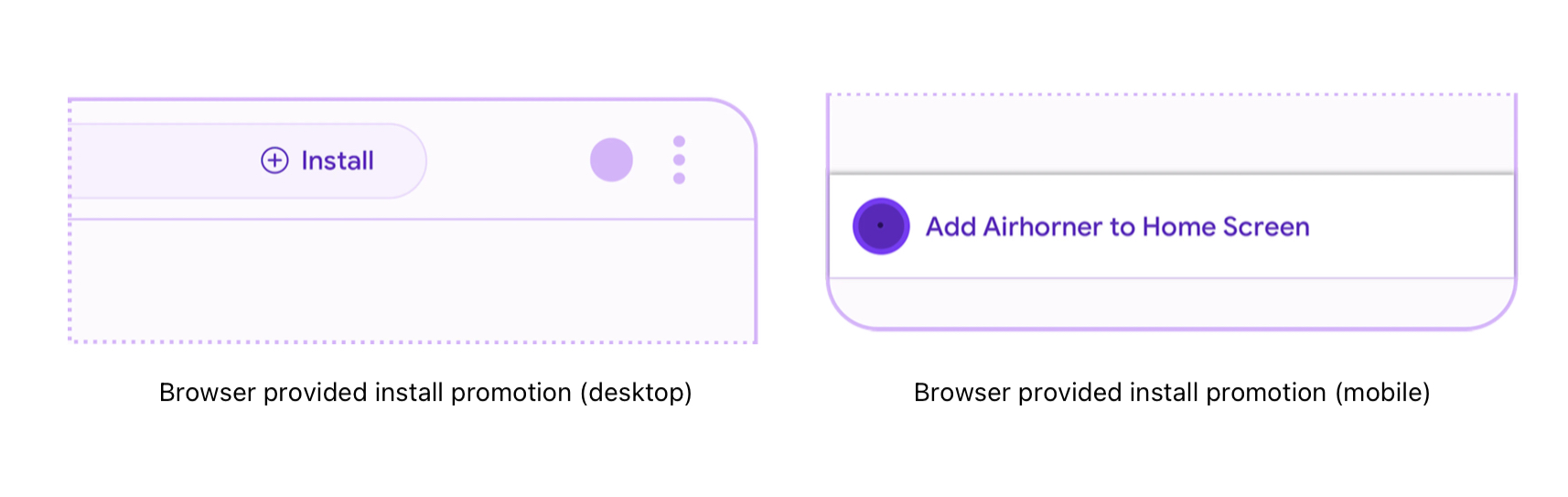
要支持 PWA,首先要求你的网站使用 HTTPS 协议,如果你的网站部署于 vercel,则天生支持。原生实现 PWA 略有些复杂,如果展开来讲,那就是另一个故事了,如果你对 PWA 感兴趣,可以去看看这份教程,其中有非常详细的介绍,不光介绍了 PWA 的基本概念,还讲了很多更好地利用 PWA 特性的实践,以及一些非代码层面的,商业上的 PWA 的价值。
nextjs 也提供了支持 PWA 的方案,我着重来讲讲该方案。
首先来介绍一下 PWA 的基本概念。PWA 有两个最重要的概念— Manifest 和 Service Worker。
Manifest
manifest 是一份描述性文件,它可以是任何名字,但通常被命名为 manifest.json。规范建议的扩展名为 .webmanifest,但是浏览器也支持 json 格式,这更便于开发者理解。manifest 需被放于项目根目录,它提供了网站的一些描述性信息,比如名称、描述、主屏图标、启动图标等。
{
"short_name": "Weather",
"name": "Weather: Do I need an umbrella?",
"icons": [
{
"src": "/images/icons-192.png",
"type": "image/png",
"sizes": "192x192"
},
{
"src": "/images/icons-512.png",
"type": "image/png",
"sizes": "512x512"
}
],
"start_url": "/?source=pwa",
"background_color": "#3367D6",
"display": "standalone",
"scope": "/",
"theme_color": "#3367D6",
"shortcuts": [
{
"name": "How's weather today?",
"short_name": "Today",
"description": "View weather information for today",
"url": "/today?source=pwa",
"icons": [{ "src": "/images/today.png", "sizes": "192x192" }]
},
{
"name": "How's weather tomorrow?",
"short_name": "Tomorrow",
"description": "View weather information for tomorrow",
"url": "/tomorrow?source=pwa",
"icons": [{ "src": "/images/tomorrow.png", "sizes": "192x192" }]
}
],
"description": "Weather forecast information",
"screenshots": [
{
"src": "/images/screenshot1.png",
"type": "image/png",
"sizes": "540x720"
},
{
"src": "/images/screenshot2.jpg",
"type": "image/jpg",
"sizes": "540x720"
}
]
}
一些关键属性——
short_name and/or name
这两个属性是必须包含的属性之一。如果两个属性都提供了,short_name 将被展示于桌面应用名称以及应用加载时,name 将被用于应用被安装时的展示名称。
icons
icons 是一个存放 app 图标的数组,每个数组元素需包含 src, sizes 属性以及图片的类型(type)。对于 chrome 来说,你需要至少提供 192x192 和 512x512 两种尺寸的图标,chrome 会自动缩放图标以适应不同设备。
start_url
start_url 是必须包含的属性之一,它规定了打开应用时展示网站的哪个路由。
manifest 中还有很多其它有用的属性,比如你可以设置你的应用头部的主题色,设置首次打开应用的加载页的颜色,设置应用头部具有哪些功能等…详细的属性清单可以在这里找到。
Service Worker
Service Worker 是谷歌推出的 web api,用于拦截和响应你的网络请求。基于 service worker,你可以实现页面的离线缓存、消息推送等功能。
service worker 细讲起来还是很复杂的,我在此不做赘述,下面来介绍一下如何让 nextjs 应用支持 PWA。
next-pwa
next-pwa 是 nextjs 官方提供的 PWA 解决方案,其实就是帮你实现了 service worker,你只需要提供 manifest 即可让你的 nextjs 应用支持 PWA 功能。
第一步、安装 next-pwa
首先安装 npm 包——
npm i next-pwa
第二步、配置 nextjs 配置文件
然后你需要简单配置一下你的 next.config.js ——
const withPWA = require('next-pwa');
module.exports = withPWA({
... // 其它配置
pwa: {
dest: 'public',
},
});
关于配置项你可以去上方的 github 链接查看。
next-pwa 会生成 service worker 所需的文件并放置于 public 文件夹下,简单场景下你不用担心 service worker 的问题,接下来只需要编写 manifest 就行了。
第三步、添加 manifest 文件
{
"name": "PWA App",
"short_name": "App",
"icons": [
{
"src": "/icons/android-chrome-192x192.png",
"sizes": "192x192",
"type": "image/png",
"purpose": "any maskable"
},
{
"src": "/icons/android-chrome-384x384.png",
"sizes": "384x384",
"type": "image/png"
},
{
"src": "/icons/icon-512x512.png",
"sizes": "512x512",
"type": "image/png"
}
],
"theme_color": "#FFFFFF",
"background_color": "#FFFFFF",
"start_url": "/",
"display": "standalone",
"orientation": "portrait"
}
将一份 manifest.json 文件存放于 public 文件夹下,文件具体内容根据自己需要来做调整。
第四步、添加 manifest 的 link 标签到 html head
<link rel="manifest" href="/manifest.json">
此时你的应用应该已经支持 PWA 了,但是还有一些地方体验不太好。
第五步、添加离线页
此时如果用户在离线时访问你的 PWA 应用,除了被缓存的页面,访问其它页面时会直接得到系统的无网络错误。
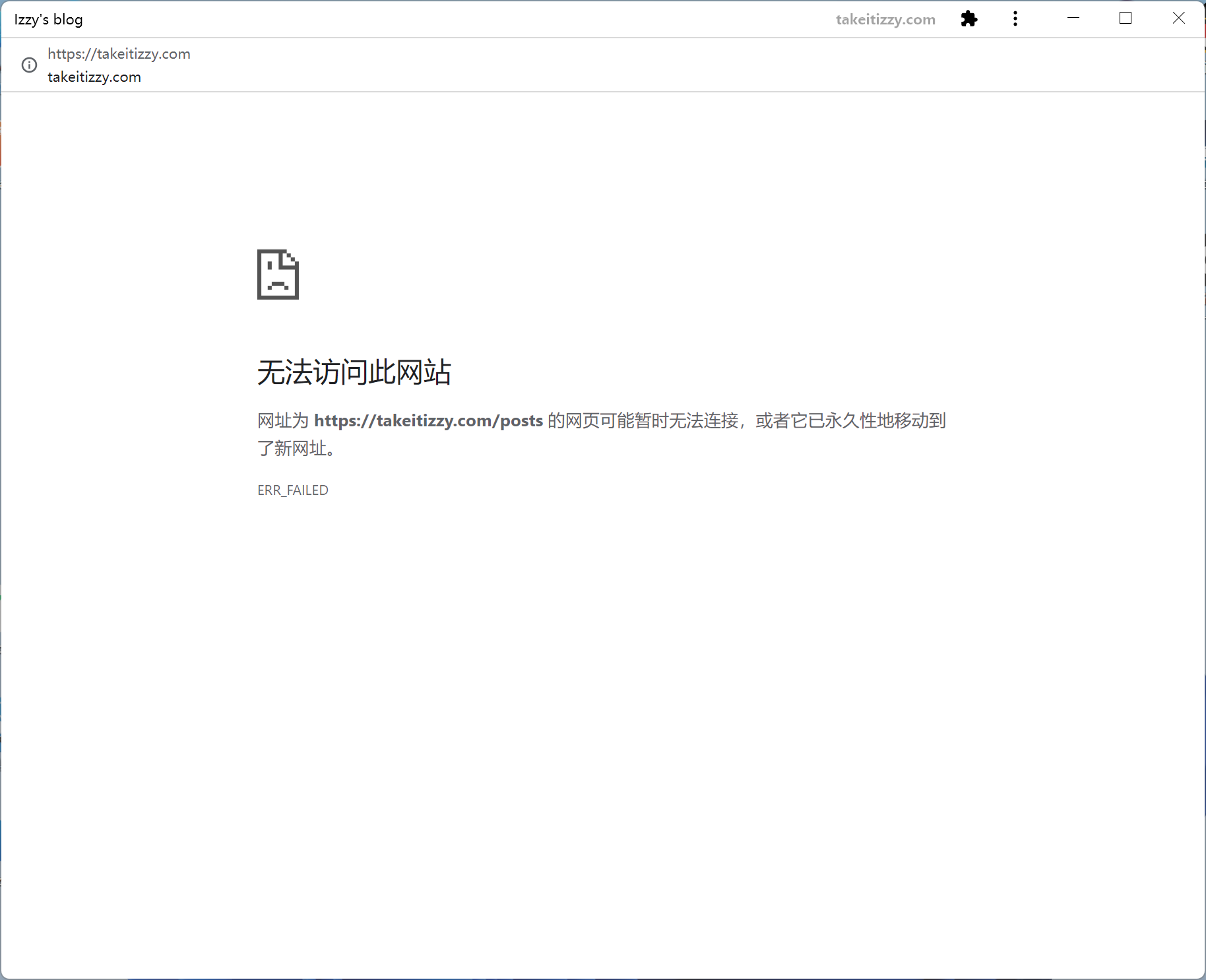
这样的体验对用户并不友好,即使在离线状态下,用户的任何操作都没有什么意义,但也应该给他提供些什么东西。
此时我们可以添加一个 _offline 页面,当用户访问未缓存页面时,将展示该页面。
在 pages 文件夹下新建 _offline.js 或 _offline.tsx ——
const OfflinePage = () => {
return <h1>你好像没网了,检查一下网络吧!</h1>
};
export default OfflinePage;
然后再进入没有被缓存过的页面,就会展示我们的离线页了。

一些提升网站用户体验的细节
art direction
art direction,直译过来是艺术指导,就是为网站在桌面端和移动端使用不同的图片,这可以通过 h5 的 <picture> 实现,这里有一篇文章讲得非常好。
为网站在不同设备上使用不同的图片,有两点原因——
- 桌面端的高清图片对于移动端来说太大了。移动端的视口很小,并不需要那么高分辨率的图片。如果在移动端依然使用桌面端的素材,一个页面会吃掉用户几十 M 流量,这样是不友好的。
- 桌面端屏幕是横的,而移动端是竖的。这样会导致横屏的图片在移动端显示怪异。假设有一张宽度为 100vw 的图片,如果需要等比缩放,那如果这张图片是横着的,在移动端就显得太小了,相反,如果这张图片是竖着的,在桌面端又太大了。如果针对不同视口对图片进行裁切(对 img 标签应用
object-fit属性),由于不同设备尺寸比例不同,同样的构图可能会在不同的设备造成显示内容上的缺失。
为你的图片写死宽高
这也是对用户很友好的一个细节,如果你不为图片写死宽高,会造成页面图片位置高度坍塌。在页面刚刚被加载时,图片位置的高度为 0,下面的 DOM 元素被顶上来,当请求到图片后再展示正常高度,这会让你的网站看起来很奇怪。
如果你的图片体积太大,先用低分辨率图片占位
在你的图片加载过程中,DOM 节点的背景是透明的,如果你的图片体积很大,会看到一片空白慢慢被填充为图片,这种体验也很不好。
此时你可以先请求一个低分辨率图片,这种图片体积很小,会被瞬间加载,再请求高分辨率图片将其覆盖,以保证用户一直可以看到什么东西。